
Large language models decide which citations to include by retrieving external sources at query time and evaluating them across multiple expanded sub-queries. Rather than relying on a single ranking, they prioritise sources that show consistent relevance and visibility across related intents.
Large language models (LLMs) do not “remember” the live web. They are trained on vast datasets with a defined cut-off date. Any information published after that point is not part of the core model. That is why many modern systems rely on retrieval processes to surface up-to-date information and attach citations to their answers.
If there is no retrieval layer, there is usually no citation. The model can generate fluent text from its training data, but it cannot point to a current, verifiable source. Citations typically appear only when a retrieval-augmented pipeline is in place.
Training Data vs Real-Time Retrieval
All foundation models have a knowledge cut-off. For example, if a model is finalised in May, it cannot natively “know” what was published in June. To bridge that gap, many systems use Retrieval-Augmented Generation (RAG). This method allows the model to query external search indexes or document stores at runtime.
In simple terms, the model does not just answer from memory. It searches, retrieves, ranks, and then generates.
Prompt Fan-Out: Why One Question Becomes Many
When you submit a prompt, the system may expand it into several smaller queries. This is often called “fan-out”.

Take this example:
I need a PDF software that allows me to save a PDF to Word and edit it.
Instead of sending that exact sentence to a search engine, the system may break it into sub-queries such as:
- Best PDF editing software
- Convert PDF to Word software
- Edit PDF after converting to Word
- PDF to DOCX tools comparison
This expansion improves coverage. It captures subtopics, entities, and user intent variations. It also increases the chance of retrieving comprehensive and current information.
How Sources (citations) Are Evaluated
Once results are retrieved, the system evaluates them across several dimensions:
- Relevance to each sub-query
- Topical consistency
- Frequency of appearance across different query paths
- Domain authority signals
- Sentiment alignment and contextual fit
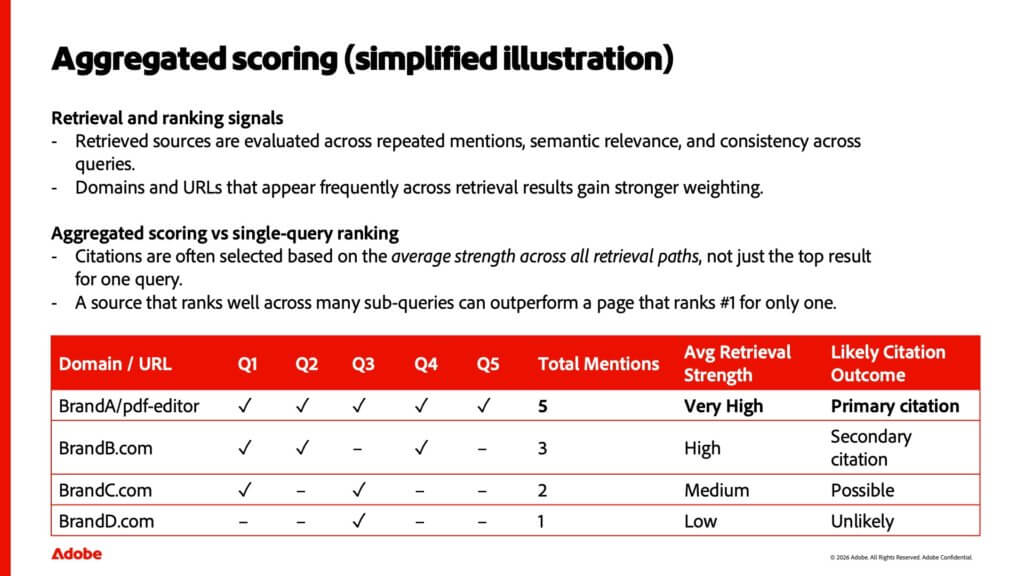
Here is the crucial point: citations are rarely chosen from a single ranking position. They are often selected based on aggregate visibility across multiple fan-out queries.
If Brand A appears consistently across “best PDF editor”, “convert PDF to Word”, and “edit PDF tool comparison”, it may outrank a competitor that ranks first for only one query. Consistency across sub-intents increases average retrieval strength.
This behaviour aligns with principles seen in large-scale information retrieval systems such as BERT-based ranking, where semantic coverage and contextual relevance matter more than exact keyword matching.
Why You Sometimes See Links — and Sometimes Do Not
If the model uses RAG, citations can be attached to specific claims. These links are retrieved from external sources at query time.
If the model responds purely from its trained parameters, any URLs mentioned in the text are generated content. They are not dynamically retrieved references. In that case, they are not citations in the strict retrieval sense.
So the rule is simple:
- No retrieval layer → no genuine citation
- Retrieval layer present → citations selected from ranked results
What This Means for SEO and GEO Strategy
This has direct implications for search optimisation and generative engine optimisation.
LLMs do not cite a brand simply because it ranks position one for a single keyword. They cite brands that demonstrate consistent topical strength across multiple related queries.
The practical takeaway is clear:
- Cover the topic in depth
- Address sub-intents explicitly
- Rank for variations of the core query
- Maintain consistent brand visibility across related searches
When your content appears repeatedly across fan-out queries, your average retrieval strength increases. That increases the probability of citation.
In other words, citation likelihood is not driven by a single ranking. It is driven by aggregate visibility across multiple intent paths.
Depth Beats Position
A site ranking ninth but covering every sub-intent thoroughly may outperform a site ranking first for one narrow query. Retrieval systems reward breadth, consistency, and contextual alignment.
For practitioners, this reinforces a familiar truth. Traditional SEO still matters. Strong technical foundations, structured content, and first-page visibility remain essential. But depth and topical completeness are now equally critical.
Final Thoughts
Large language models select citations based on aggregated retrieval signals across expanded query paths. They evaluate frequency, relevance, and consistency rather than relying on a single top-ranking result.
If you want to be cited, you must be visible across the ecosystem of related queries. Comprehensive coverage increases retrieval strength. Retrieval strength increases citation probability.
SEO is not obsolete. It has simply become multidimensional.